Part 2: Evolution - Three Critical Shifts in the AI Security Landscape


In Part 1 of this series, we explored how AI agents—autonomous systems capable of perceiving, deciding, and acting—are transforming enterprise technology. We examined their core components (Brain, Perception, and Action modules) and why these systems matter now more than ever.
Today, we'll examine three fundamental shifts in how AI systems have evolved—transitions that have dramatically altered the security landscape. These aren't just technical changes; they represent fundamental transformations in how AI systems operate, the risks they pose, and the challenges organizations face in securing them.
The Evolution Creates New Attack Surfaces
The evolution of artificial intelligence has brought about fundamental changes in how AI systems are architected and deployed. As these systems become more sophisticated, they've gained significant capabilities while also introducing new attack surfaces and vulnerabilities that could put organizations at risk. At the heart of many modern AI systems are pre-trained language models (PLMs), which serve as the foundation for increasingly sophisticated AI agents.
Understanding PLM Vulnerabilities in Modern AI Systems
Researchers have found that pre-trained language models (PLMs) are particularly susceptible to adversarial attacks, manipulating the models behaviour to produce intentionally wrong outputs, or evade safety controls. While adversarial attacks on standard LLMs might be contained to a single system or task, LLM-based agents integrate with multiple systems through their action modules - accessing tools, databases, and APIs. This broader system access means a single compromised decision can trigger multiple downstream actions across connected systems.
AI Architecture Vulnerabilities
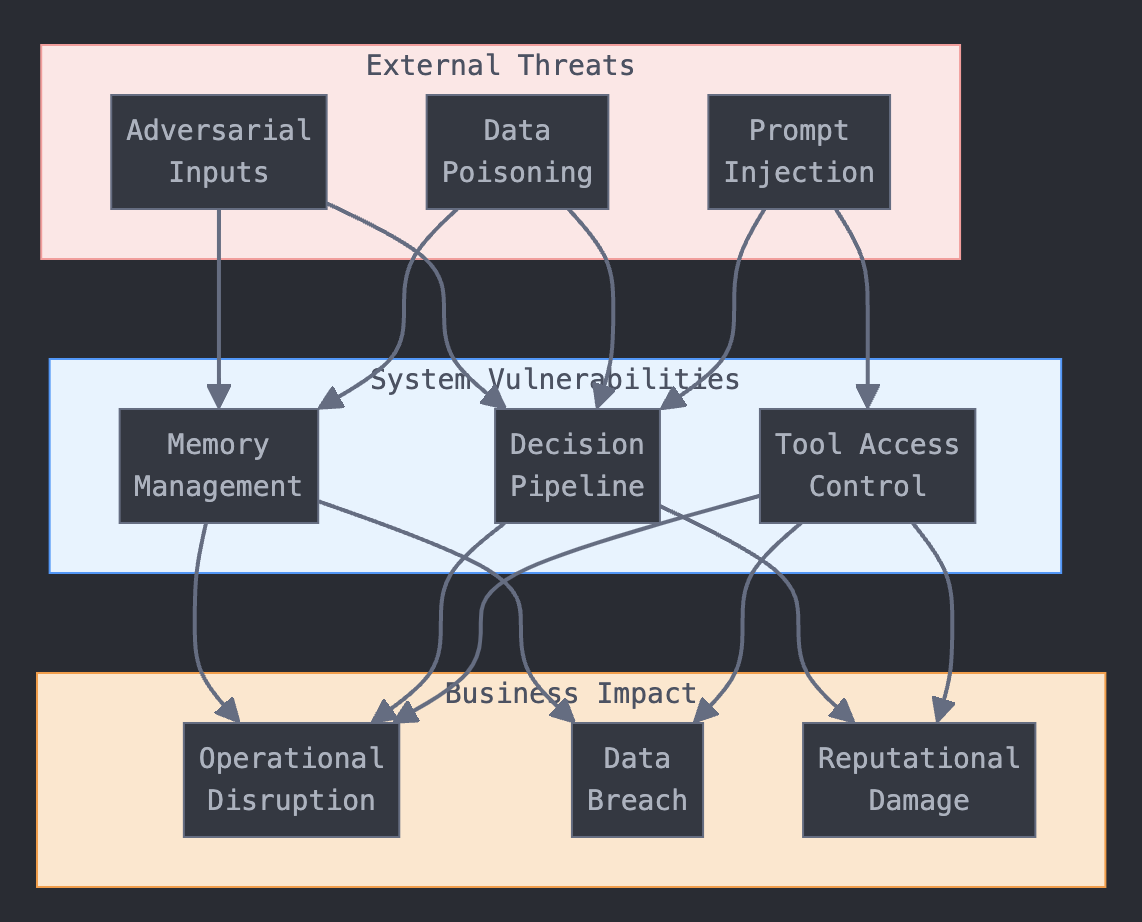
AI Threat Flow Diagram
These vulnerabilities surface through multiple attack vectors:
- Dataset poisoning: Attackers can manipulate the training data to embed harmful behaviors
- Backdoor attacks: Hidden triggers can be planted to make the model behave maliciously in specific situations
- Prompt-specific attacks: Carefully crafted inputs can override the model's safety controls
- Multi-modal vulnerabilities: Adversarial inputs from images or audio can deceive the perception module
- Action module exploitation: Maliciously modified instructions can trigger harmful real-world actions
Key Security-Impacting Transitions
Rules-based to Learning-based Evolution
Early AI systems were built on symbolic AI foundations, employing logical rules and symbolic representations to replicate human reasoning patterns in an explicit and interpretable way. However, this approach gave way to more dynamic, learning-based agents as the field progressed. The transition began with reactive agents that could interact with their environments in real-time, followed by the integration of reinforcement learning (RL) which enabled agents to learn and improve through experience rather than relying solely on pre-programmed rules.
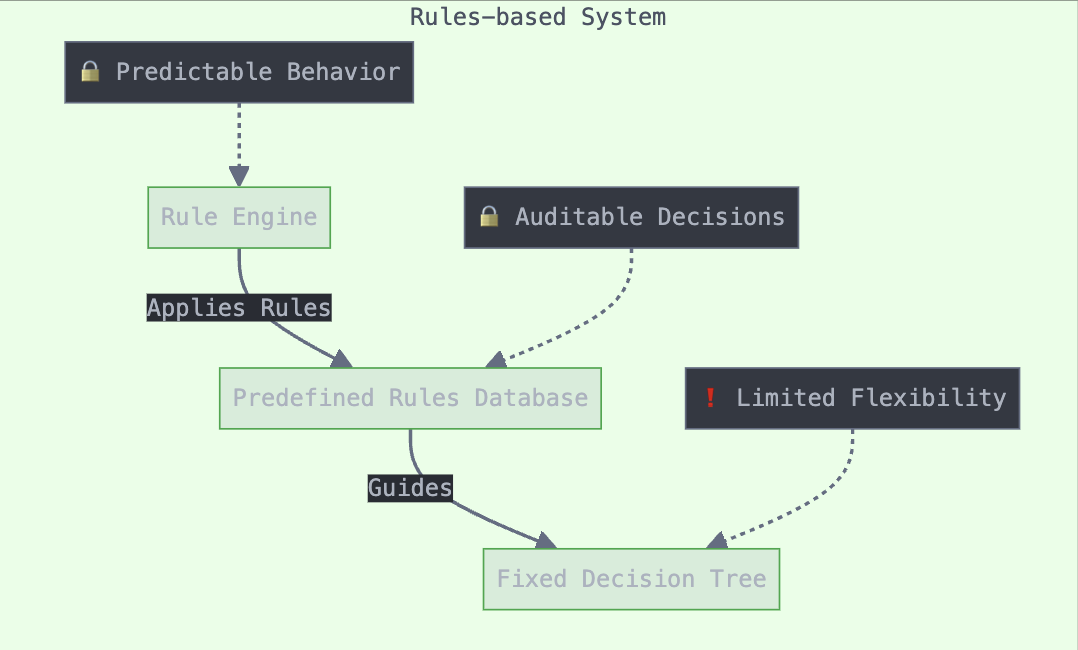
Fig 1. Rules-based
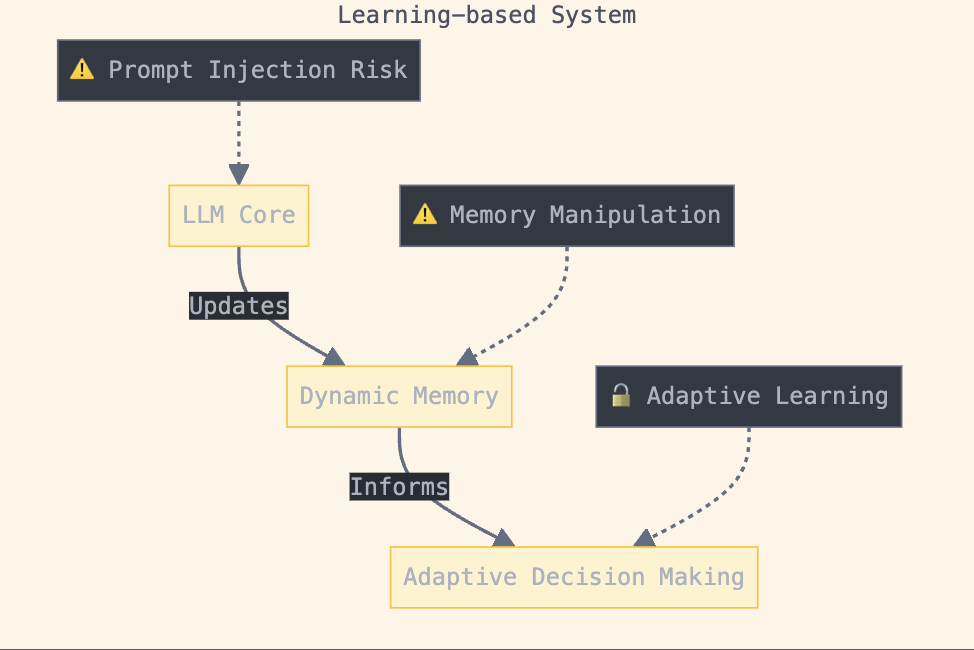
Fig 2. Learning-based
Security Implications:
Critical Vulnerabilities:
- Prompt injection susceptibility: LLMs can be subverted by malicious prompts that override their intended purpose
- Infection propagation: In multi-agent systems, a compromised learning-based agent can spread the "infection" to other agents
- Memory manipulation: Attackers can manipulate memory retrieval by inflating the importance score of malicious prompts
- Instruction hierarchy fragility: Learning-based models often lack structured hierarchies for processing instructions, so an attacker could bypass security measures by injecting instructions that the model might prioritise over its own safety instructions.
Systemic Challenges:
- Transparency gaps: Learning-based systems create "black box" decision-making
- Data vulnerability: AI queries and responses can be manipulated for theft or corruption
- Bias perpetuation: Learning-based systems may amplify biases present in training data
Single-task to Multi-task Progression
Initially, agents were designed for specific, narrow tasks. The field has evolved toward multi-task agents capable of handling diverse responsibilities, including multi-modal processing of text, images, and audio. Multi-agent systems (MAS) have emerged to tackle complex problems through collaboration between specialised agents.
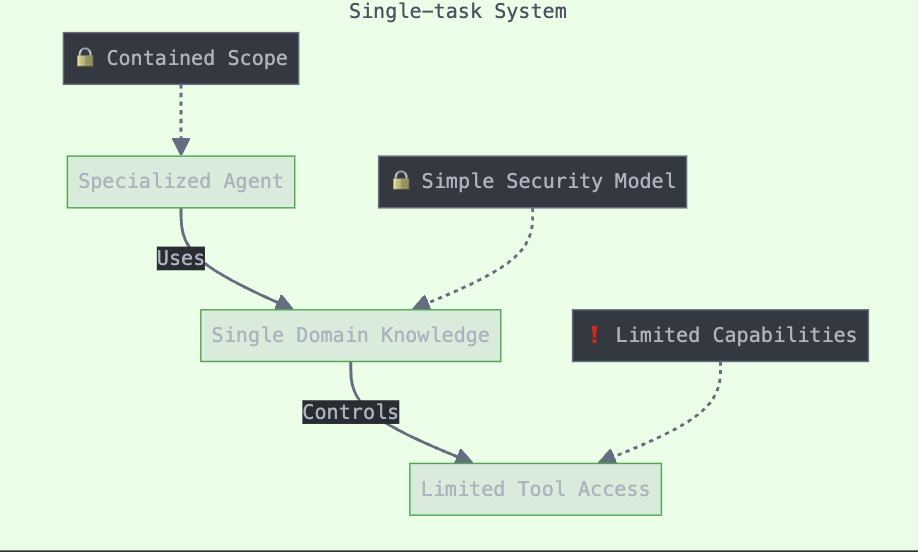
Fig 3. Single-Task
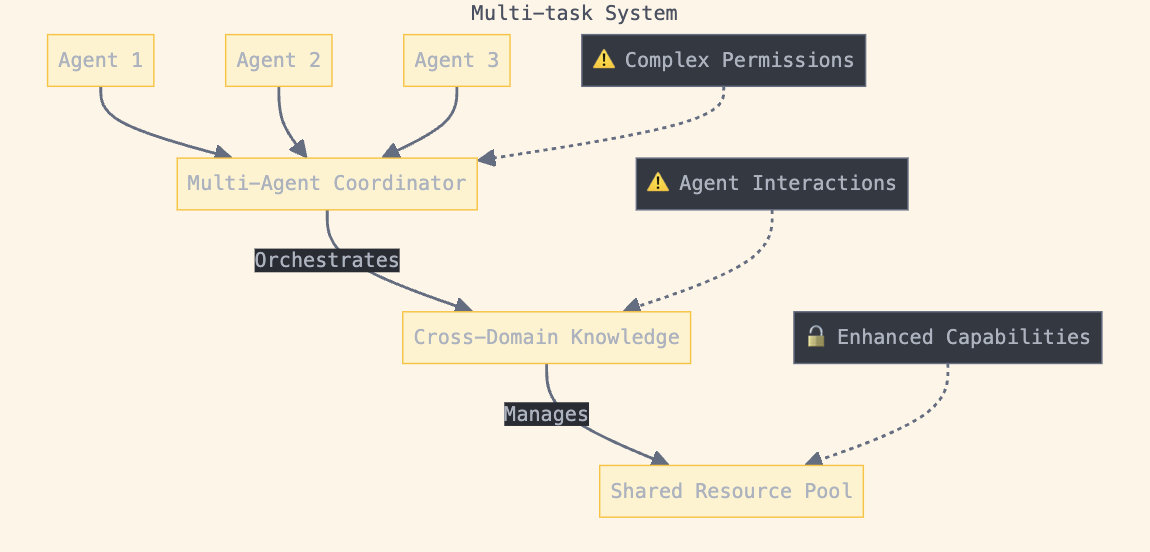
Fig 4. Multi-Task
Security Implications:
Architectural Vulnerabilities:
- Expanded attack surface: Direct database access creates multiple entry points
- Complex infection pathways: Coordinated attacks can exploit multiple agents simultaneously
- Insufficient defences: Current agent-level protections struggle with core LLM vulnerabilities
Operational Challenges:
- Context maintenance: Difficulty maintaining awareness across extended interactions
- Social simulation risks: Unsecured memory retrieval systems expose simulations to prompt infection
- Coordination exploitation: Attackers can leverage agent-to-agent communication channels
Tool-using to Tool-creating Advancement
Early agents had limited interaction with their environment. Modern agents not only use existing tools but can create new ones by abstracting task requirements or integrating existing capabilities. This includes generating executable programs and even debugging themselves.
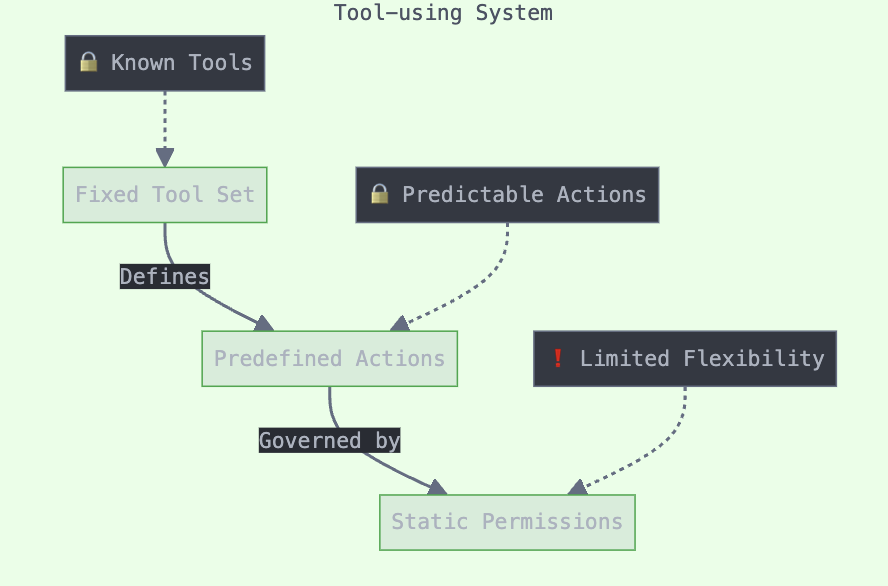
Tool Use
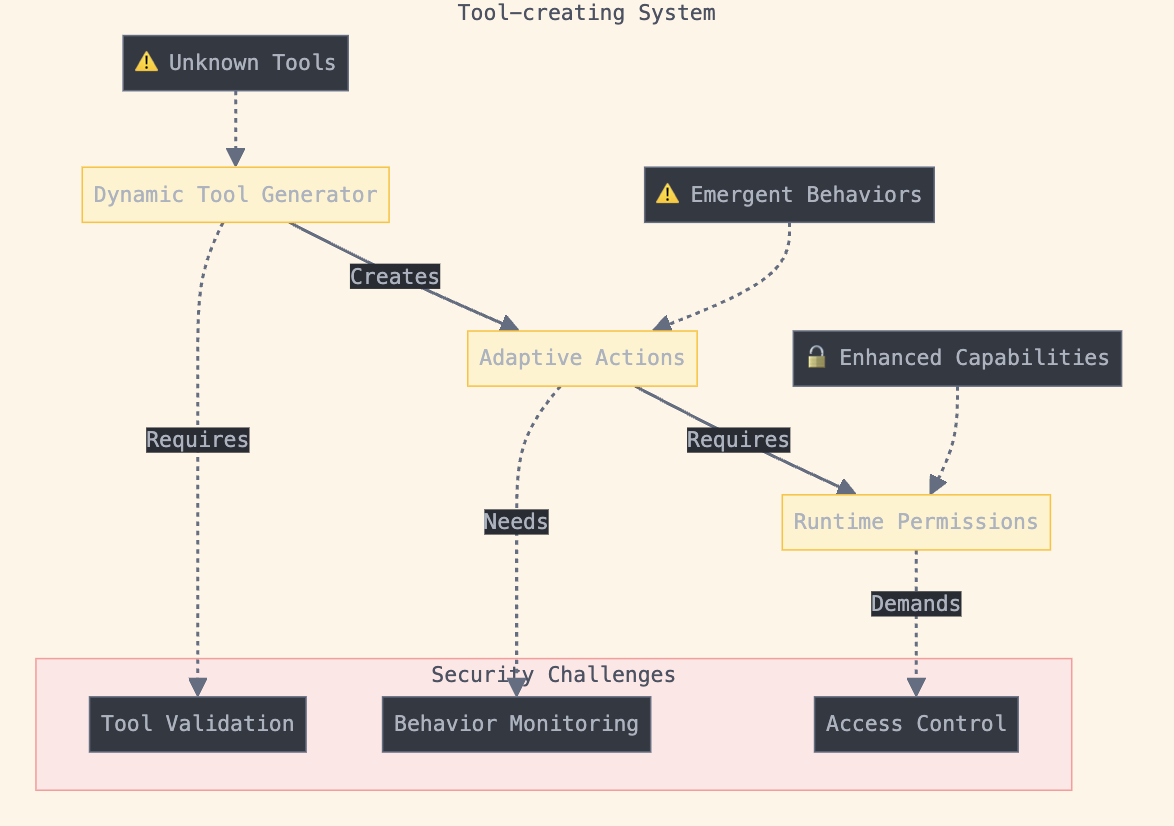
Tool Creating
Security Implications:
Primary Concerns:
- Novel attack vectors: Generative AI can identify vulnerabilities and create new attack scenarios
- Dual-use capabilities: AI agents can be weaponised for both offensive and defensive purposes
- Gateway risks: Compromised AI agents can enable unauthorised access to sensitive systems
Emerging Challenges:
- Detection complexity: Traditional security monitoring may miss AI-generated threats
- Rapid evolution: Security measures must adapt to keep pace with AI tool creation
- Ethical boundaries: Tool-creating capabilities raise questions about autonomous system limits
Practical Implications
With such dramatic shifts in system complexity and architecture, you would be forgiven for assuming we need to completely reinvent our security practices. However, the opposite is true. Organisations adopting advanced AI systems should recognise that fundamental security principles remain more relevant than ever.
The core practices that security professionals have long advocated – principle of least privilege, defence in depth, threat modelling, and robust authentication and authorisation – provide the essential foundation for securing AI systems.
Take the principle of least privilege, for example. Just as we've always limited user access to only what's necessary for their role, this same principle becomes even more crucial when applied to AI agents that can interact with multiple systems and make autonomous decisions.
The principle hasn't changed – we're just applying it to a more sophisticated actor.
What changes is not these fundamental principles, but rather how we apply them to AI's unique characteristics:
- For learning-based systems: Traditional input validation expands to include monitoring training data integrity and model behaviour
- For multi-task systems: Principle of least privilege becomes even more critical when managing permissions across multiple AI capabilities
- For tool-creating systems: Standard runtime monitoring practices adapt to track AI-generated code and tools
The 'beast' may look different, but the principles of securing interconnected systems remain the same. Organisations that maintain strong security fundamentals while understanding AI's specific characteristics will be better positioned to manage these emerging technologies safely.
Key Takeaways
Understanding these three evolutionary shifts is crucial for security professionals:
- Learning-based systems introduce unpredictability and new attack vectors like prompt injection
- Multi-task capabilities expand attack surfaces and create complex interaction patterns
- Tool-creating abilities enable novel threats that traditional security models weren't designed to handle
The fundamental security principles remain valid, but their application must evolve to address AI's unique characteristics.
Continue the Series
Next up: Part 3: The Anatomy of AI Agents - Security Vulnerabilities, where we'll take a technical deep dive into the anatomy of modern AI agents, examining specific vulnerabilities in each core component.
Previous: Part 1: The Rise of Agentic AI - A Security Perspective
Questions about AI evolution and security? Reach out via LinkedIn or email.
Further Reading
- Zhang, C., et al. "The Rise and Potential of Large Language Model Based Agents: A Survey" (2023)
- Zhu, K., et al. "PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts" (2023)
- Chen, X., et al. "How Robust is GPT-3.5 to Predecessors? A Comprehensive Study on Language Understanding Tasks" (2023)
- Qiao, Z., et al. "CREATOR: Tool Creation for Disentangling Abstract and Concrete Reasoning of Large Language Models" (2023)
- Gu, T., et al. "Identifying Vulnerabilities in the Machine Learning Model Supply Chain" (2017)
- Chen, X., et al. "BadNL: Backdoor Attacks Against NLP Models" in ACSAC '21: Annual Computer Security Applications Conference (2021)
- Li, Z., et al. "BFClass: A Backdoor-Free Text Classification Framework" in Findings of ACL: EMNLP 2021
- Shi, Y., et al. "PromptAttack: Prompt-based Attack for Language Models via Gradient Search" in NLPCC 2022
- Perez, F. and Ribeiro, I. "Ignore Previous Prompt: Attack Techniques for Language Models" (2022)
- Liang, P., et al. "Holistic Evaluation of Language Models" (2022)
- Gururangan, S., et al. "Whose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection" in EMNLP 2022
- Liu, Y., et al. "Prompt Injection Attack Against LLM-Integrated Applications" (2023)