AWS Youtube Transcript Project
Project Overview
As per README.md on the repo:
"An AWS architecture project to use Lambda, DynamoDB, S3, SQS and Python to create an automated system that takes a channel id, fetches all available video transcripts and then analyses it with Amazon Transcribe to get a "vibe check" of the videos individually, and then the channel as a whole."
As at April 16th, 2023, I'm re-architecting this a bit and making notes here.
Design Decisions
What are the steps I'm trying to do here?
- get a channel_id and some channel info into a dynamodb table
- trigger a lambda function on a new channel entry into that DDB table
- lambda function takes the channel_id and fetches all the videos listed for that channel, with key
video_id - puts this list of videos, for that channel, into another DDB table, partition key =
channel_id, as new separate items, with avideo_id - another lambda function takes this the
channel_idand for eachvideo_id, fetches the transcript for that video in text format - this text format transcript is saved to an S3 bucket, with prefix=
$\{channel_id}/$\{video_id}/transcript.txt - another process is kicked off to analyse each video for sentiment, and save the "score" for it somewhere
- another process is kicked off to analyse each channel (prefix) for whole of channel sentiment "score", and saved somewhere.
Achitecture Diagram
Current as at: April 16th, 2023.
A couple things need deep diving into:
- DynamoDB streams for triggering Lambda
- Map Flow in Step Functions for taking a list video id's and doing parrallel "fetch transcript" jobs.
- Comprehend - haven't got to that part yet.
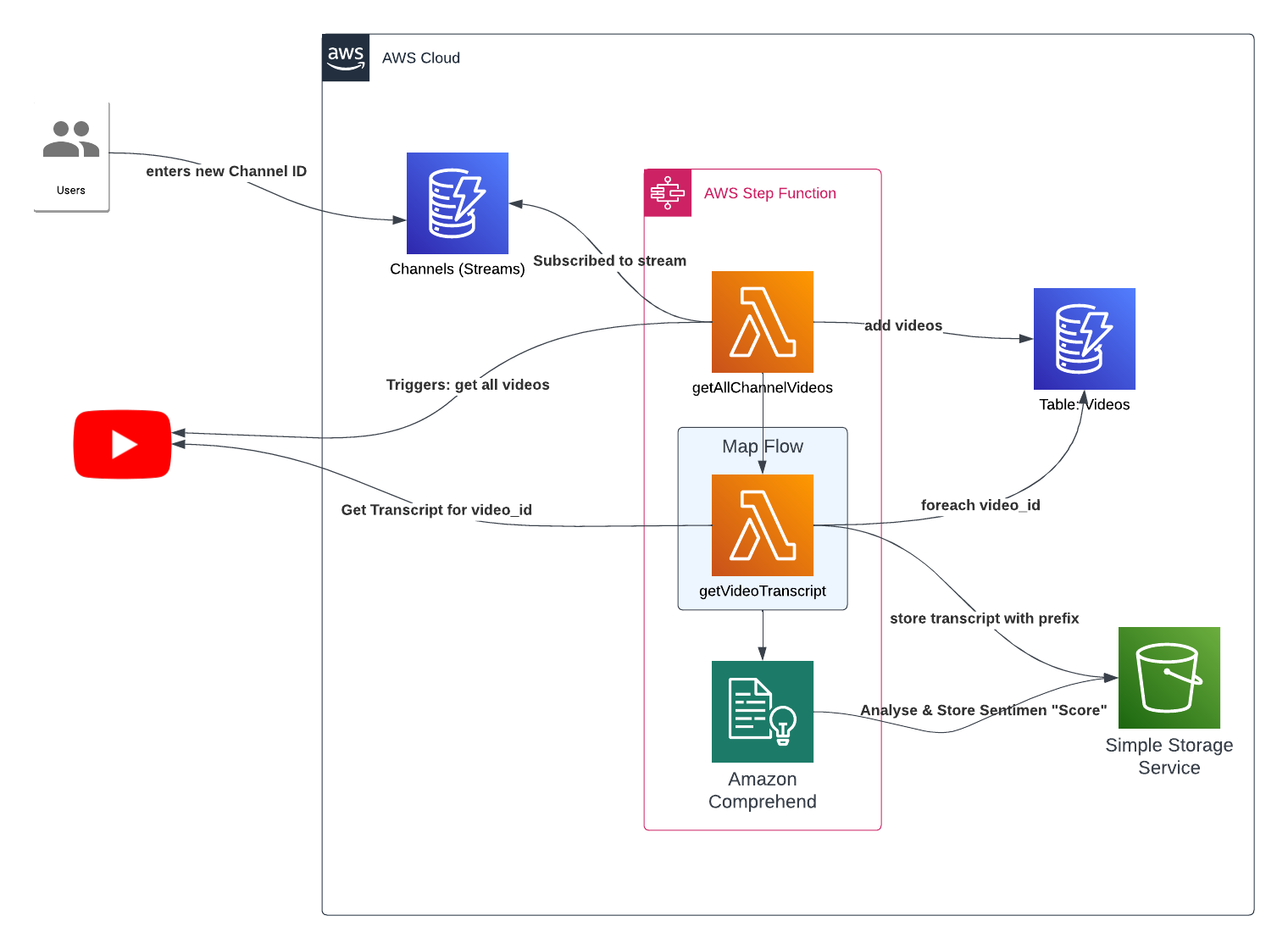
AWS Services Required
This list I think will change, possibly, as I figure out more how best to design a good solution. At first I'll be limited by my knowledge of best practices around development and systems design, and as I learn more what "good" looks like, the services may be replaced and the solution simplified in order to deliver "better".
Currently:
- AWS Lambda
- AWS Step Functions
- Amazon DynamoDB (maybe DDB Streams for triggering lambda on new channel entries?)
- Amazon S3
- Amazon Comprehend
Triggering Step Functions from DynamoDB entry
I thought about whether a bunch of parallel processing (i.e. fetch all these video transcripts in parrallel) would be better served by AWS Batch, so I asked ChatGPT to make the case:
AWS Batch is suitable when:
You need to run batch computing workloads that require high compute capacity and processing power, such as scientific simulations, data processing, and financial analysis.
1. You have a large number of jobs that need to be run in parallel, with each job requiring a different set of compute resources.
2. You need to control the amount of compute resources allocated to each job, such as CPU, memory, and storage.
3. You want to leverage managed container services, such as Docker, to run your batch jobs.
AWS Lambda is suitable when:
1. You need to run small, short-lived code snippets in response to events, such as HTTP requests, changes to a database, or uploads to a storage bucket.
2. You want to build serverless architectures that can scale automatically and handle unpredictable traffic.
3. You need to run code without managing servers, operating systems, or infrastructure.
4. You want to pay only for the compute time used, without incurring fixed costs.
Because each transcript may be small, or may not exist, or a channel may have many or few transcripts, lambda seems like the way to go.
References
A few notes on things peripheral to the core of the application I've learned as I've built things.
AWS cli lambda folders
To get this folder setup with all the relevant files, iam, templates, src, from your lambda function in AWS console e.g.
I have no idea how I generated this last time. smh.
Function Deployment
command looks like this e.g.
aws lambda update-function-code --function-name getChannelVideoList --zip-file fileb://my-deployment-package.zip
Lambda Library Layers
For various import dependencies, you need to create a "layer" in AWS Lambda for your function to pull these libraries in.
scrapetube & youtube_transcript_api
This project needs scrapetube and youtube_transcript_api, so do the following to package up a layer to upload to AWS:
# create the folder for your layer
mkdir -p layers/python
# change into, and install libraries to the folder
cd layers/python
pip install --target . <libraries />
# change up a directory, create a zip file of the `python/` folder
cd ..
zip -r <layername />.zip python
The zip contents should have the python/ directory as root.
Your layer file is ready for upload to AWS (done manually at the time via console).