Algolia Search Integration for Docusaurus - Complete Setup with Cloudflare CDN
Introduction
This is a walk-through of what it took for me to make my blog & digital garden ronamosa.io searchable using Algolia. I had the added benefit of using Cloudflare CDN in front of my website, so that needed to be taken into account as well.
If you get it all right, you get this:
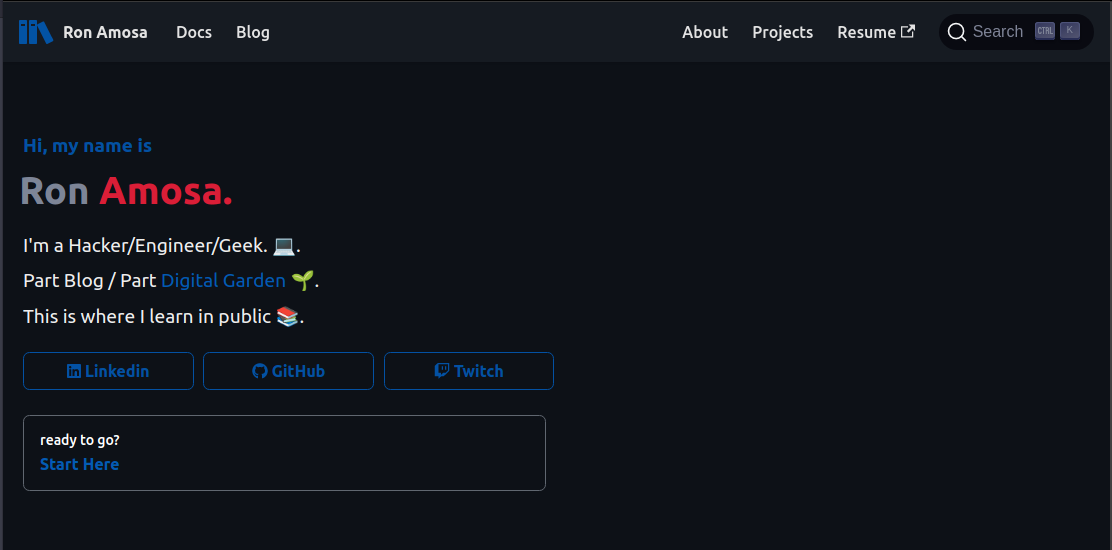
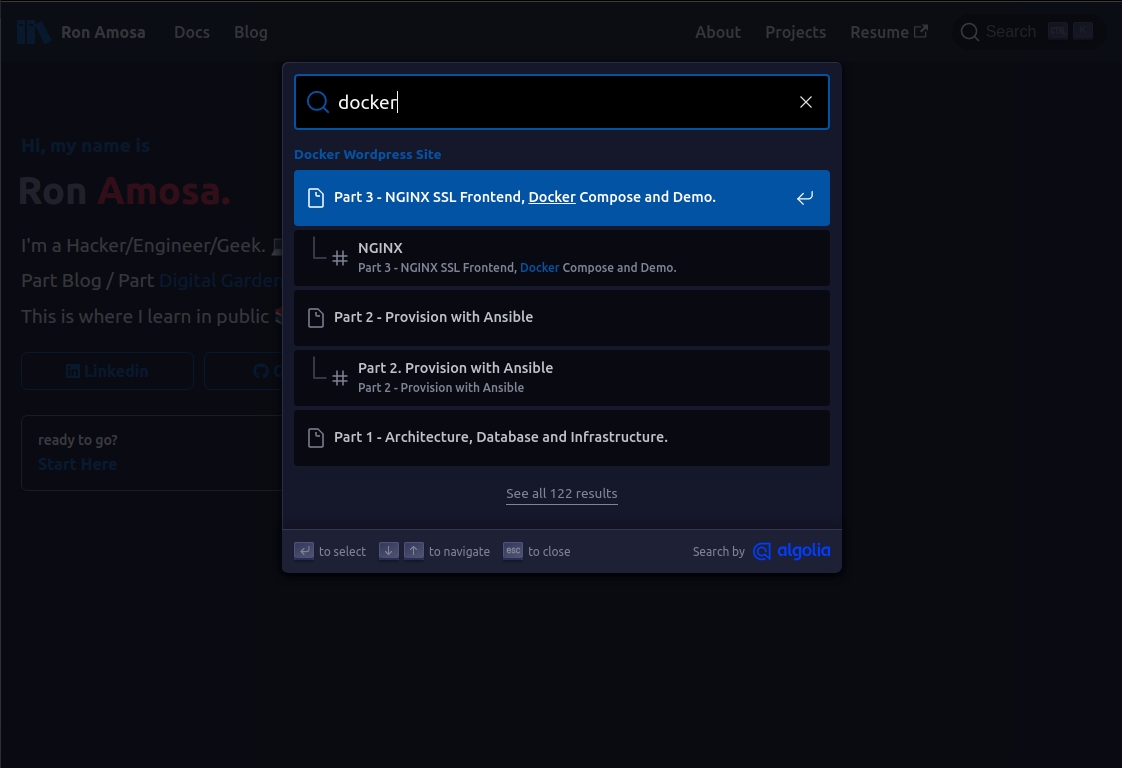
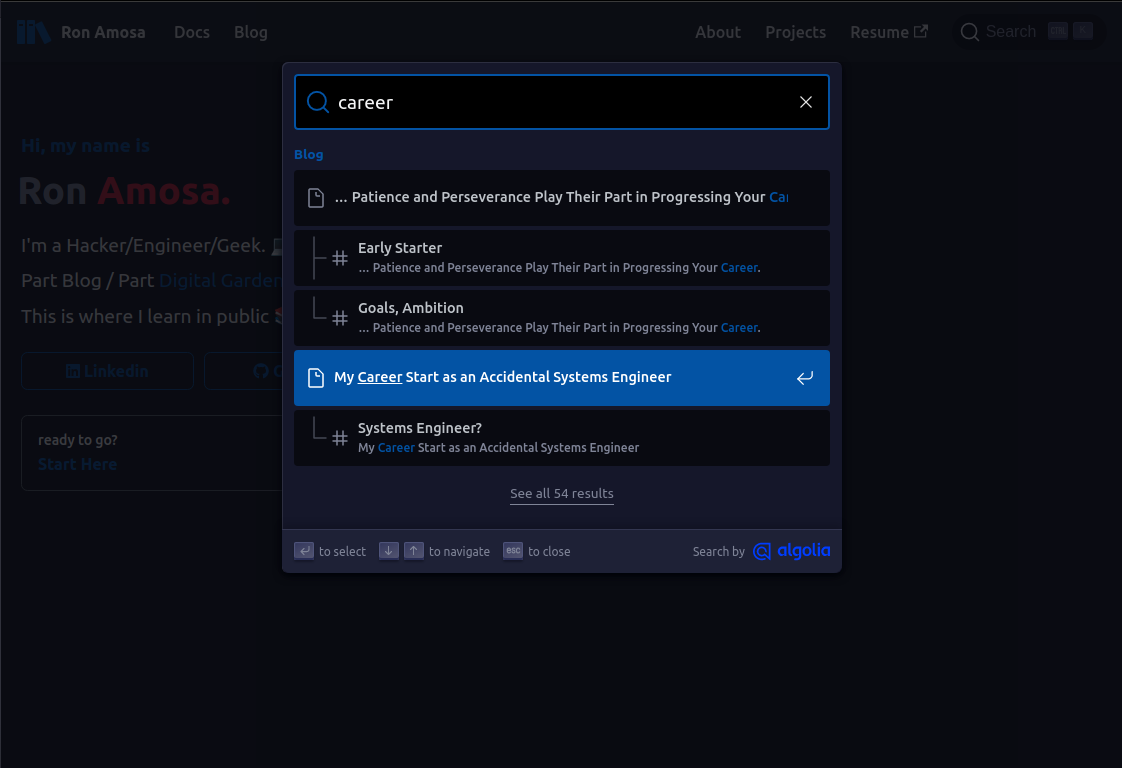
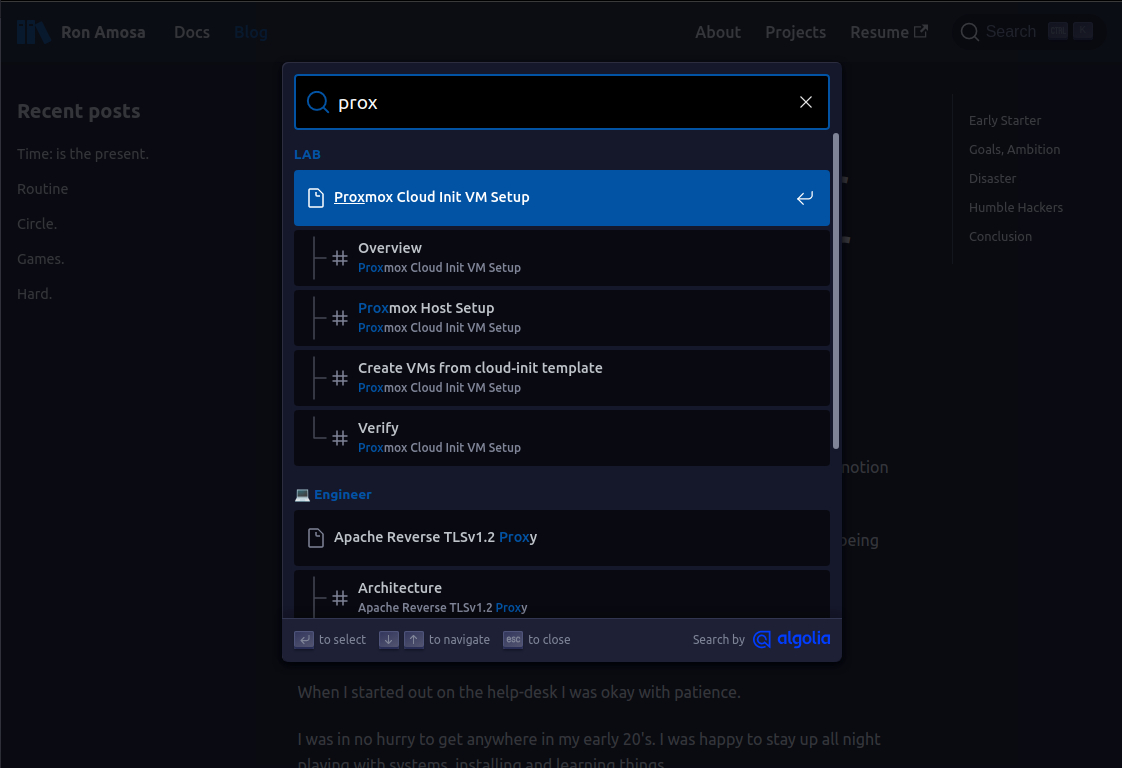
The official documentation for setting this up you can follow here: https://docusaurus.io/docs/search.
Pre-requisites
- A static site running [docusaurus v2.0](https://docusaurus.io/ v2.0)
- An Algolia Account (free)
- Note: I used my GitHub account to federate in but later on I set a password as well.
- Apply to join Algolia's Docsearch program.
- Your site needs to be publicly available (open source)
- Your site needs to be technical documentation of an open source project, or a tech blog.
Apply and wait...
Setup Algolia Crawler
Once you're accepted into the program, log into your Algolia account and go to the Algolia Crawler.
Create a Crawler

Fill in your details
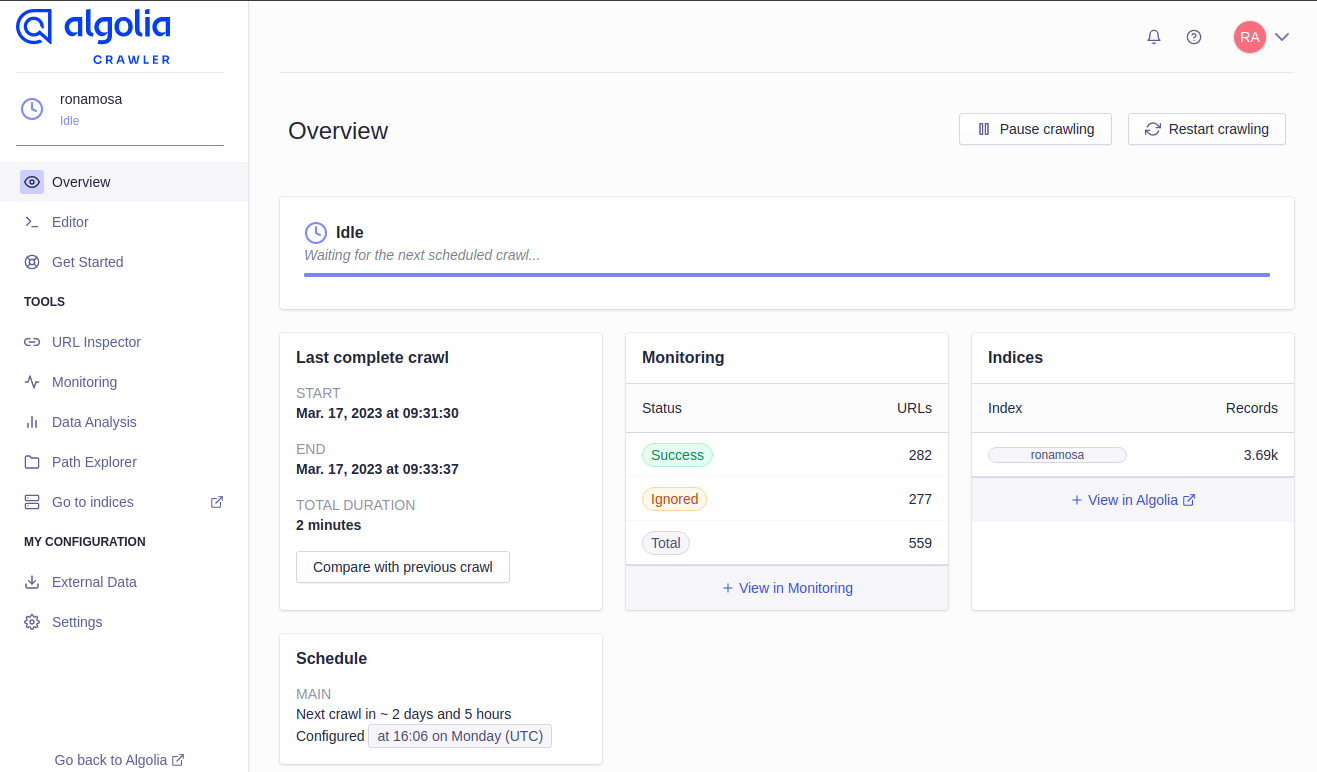
Once your crawler is ready to go, you'll see your Overview look like this:
Click >_ Editor and your config should look like this (thsi is the standard Docusaurus config):
new Crawler({
rateLimit: 8,
maxDepth: 10,
startUrls: ["https://ronamosa.io/"], // root folder crawler starts from...
renderJavaScript: false,
sitemaps: ["https://ronamosa.io/sitemap.xml"],
ignoreCanonicalTo: true,
discoveryPatterns: ["https://ronamosa.io/**"],
schedule: "at 16:06 on Monday",
actions: [
{
indexName: "ronamosa",
pathsToMatch: ["https://ronamosa.io/**"], // don't change this due to the `url_will_not_match_config` error
recordExtractor: ({ $, helpers }) => {
// priority order: deepest active sub list header -> navbar active item -> 'Documentation'
const lvl0 =
$(
".menu__link.menu__link--sublist.menu__link--active, .navbar__item.navbar__link--active"
)
.last()
.text() || "Documentation";
return helpers.docsearch({
recordProps: {
lvl0: {
selectors: "",
defaultValue: lvl0,
},
lvl1: ["header h1", "article h1"],
lvl2: "article h2",
lvl3: "article h3",
lvl4: "article h4",
lvl5: "article h5, article td:first-child",
lvl6: "article h6",
content: "article p, article li, article td:last-child",
},
aggregateContent: true,
recordVersion: "v3",
});
},
},
],
initialIndexSettings: {
ronamosa: {
attributesForFaceting: [
"type",
"lang",
"language",
"version",
"docusaurus_tag",
],
attributesToRetrieve: [
"hierarchy",
"content",
"anchor",
"url",
"url_without_anchor",
"type",
],
attributesToHighlight: ["hierarchy", "content"],
attributesToSnippet: ["content:10"],
camelCaseAttributes: ["hierarchy", "content"],
searchableAttributes: [
"unordered(hierarchy.lvl0)",
"unordered(hierarchy.lvl1)",
"unordered(hierarchy.lvl2)",
"unordered(hierarchy.lvl3)",
"unordered(hierarchy.lvl4)",
"unordered(hierarchy.lvl5)",
"unordered(hierarchy.lvl6)",
"content",
],
distinct: true,
attributeForDistinct: "url",
customRanking: [
"desc(weight.pageRank)",
"desc(weight.level)",
"asc(weight.position)",
],
ranking: [
"words",
"filters",
"typo",
"attribute",
"proximity",
"exact",
"custom",
],
highlightPreTag: '<span class="algolia-docsearch-suggestion--highlight" />',
highlightPostTag: "</span>",
minWordSizefor1Typo: 3,
minWordSizefor2Typos: 7,
allowTyposOnNumericTokens: false,
minProximity: 1,
ignorePlurals: true,
advancedSyntax: true,
attributeCriteriaComputedByMinProximity: true,
removeWordsIfNoResults: "allOptional",
},
},
appId: "9UFF3RBJQ9", // public info, save to commit.
apiKey: "1f53a6f7e7f331786250c1b092794deb", // public info, save to commit.
});
This "safe to commit" API Key is a public "search-only" key that accesses your index of already publicly available information. There is an Algolia Admin API Key, now that you don't want public or committed anywhere.
Start, or Restart your crawler and you should see results in either Success, Ignored and Total. If you see more Ignored than Success, keep working through the next steps and if the issue persists, check out the Troubleshooting section below.
Next, configure your docusaurus site to connect to, and use the algolia crawler index to provide search results to your website users.
Configure docusaurus.config.js
Update your docusaurus.config.js file to connect to your Algolia crawler index.
Mine is very minimalist, removed all optional configs, just the bare minimum configs:
module.exports = {
title: 'Ron Amosa',
// ...
themeConfig: {
//...
algolia: {
// The application ID provided by Algolia
appId: '<YOUR_APP_ID />',
// Public API key: it is safe to commit it
apiKey: '<YOUR_API_KEY />',
indexName: '<YOUR_CRAWLER_INDEX_NAME />',
},
Check any issues with your themeConfig on the docusaurus site.
(optional) Cloudflare
If you use a CDN, like cloudflare, which I do, you have to ensure your SSL/TLS encryption mode is "Full".
Scroll down to the SSL/TLS drop-down menu and click Overview
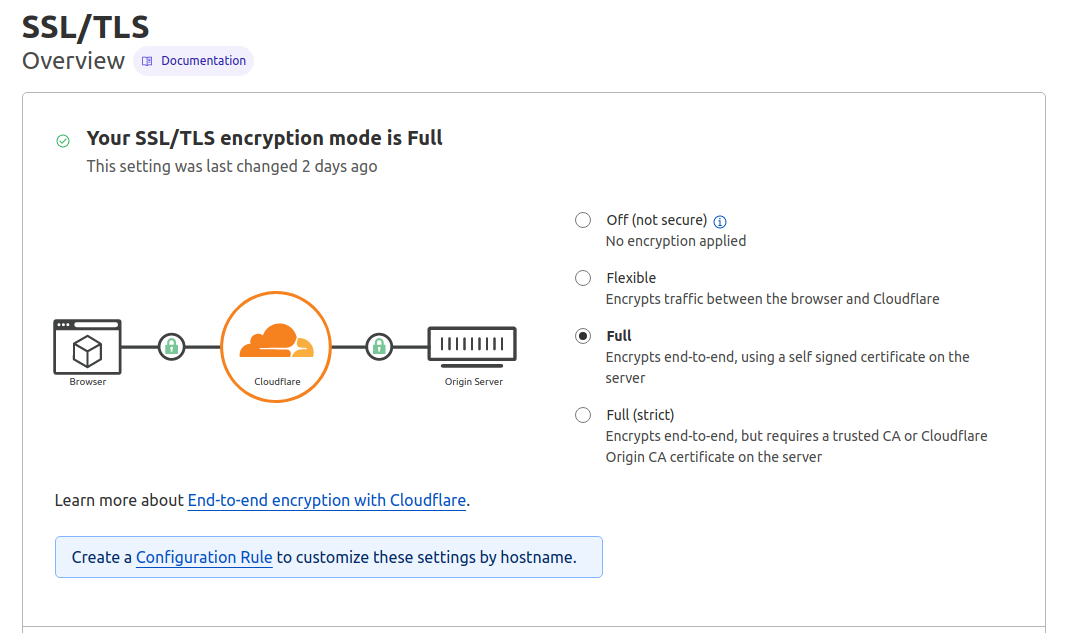
Ensure Full is selected. That's it.
Restart crawler
Go back to your Algolia Crawler and restart it to crawl your site now.
Search your site
After you save all your changes and push it to main (assuming you are hosting on GitHub Pages like me), check to see if you have a new search button that looks like this in the top right-hand corner:

Press ctrl+k and you should be able to search your site now:
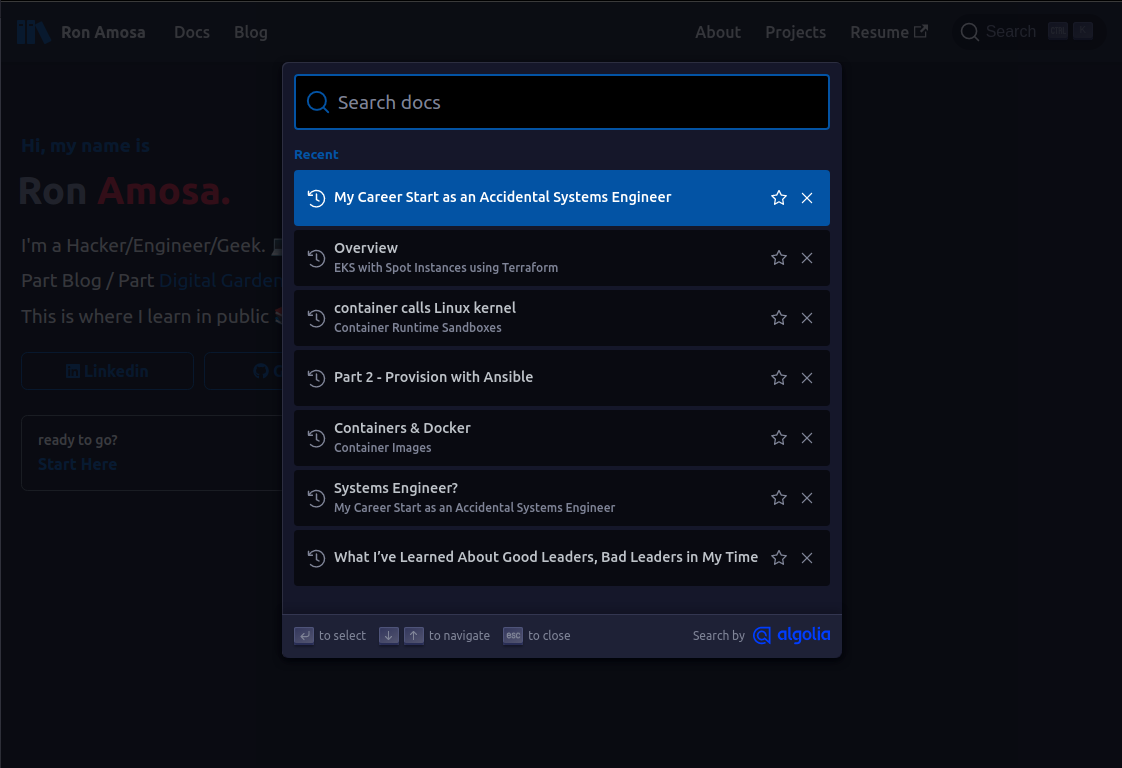
Finished!
Troubleshooting
url_will_not_match_config error
After running your crawler and you check it out in Monitoring section of your Algolia Crawler's 'Tools' section, and you see a lot of your pages are IGNORED status with 'Reason' being HTTP redirect (301, 302) Not followed and logs complain about your site trying to redirect to a http site and you see this error: url_will_not_match_config - your problem is going to be this http/s issue, and not the pathsToMatch one.
The fix for this, at least for me, was fixing my Cloudflare SSL/TLS settings.