PrivateGPT on AWS EC2 - Secure Cloud-Based Document Chat with LLMs
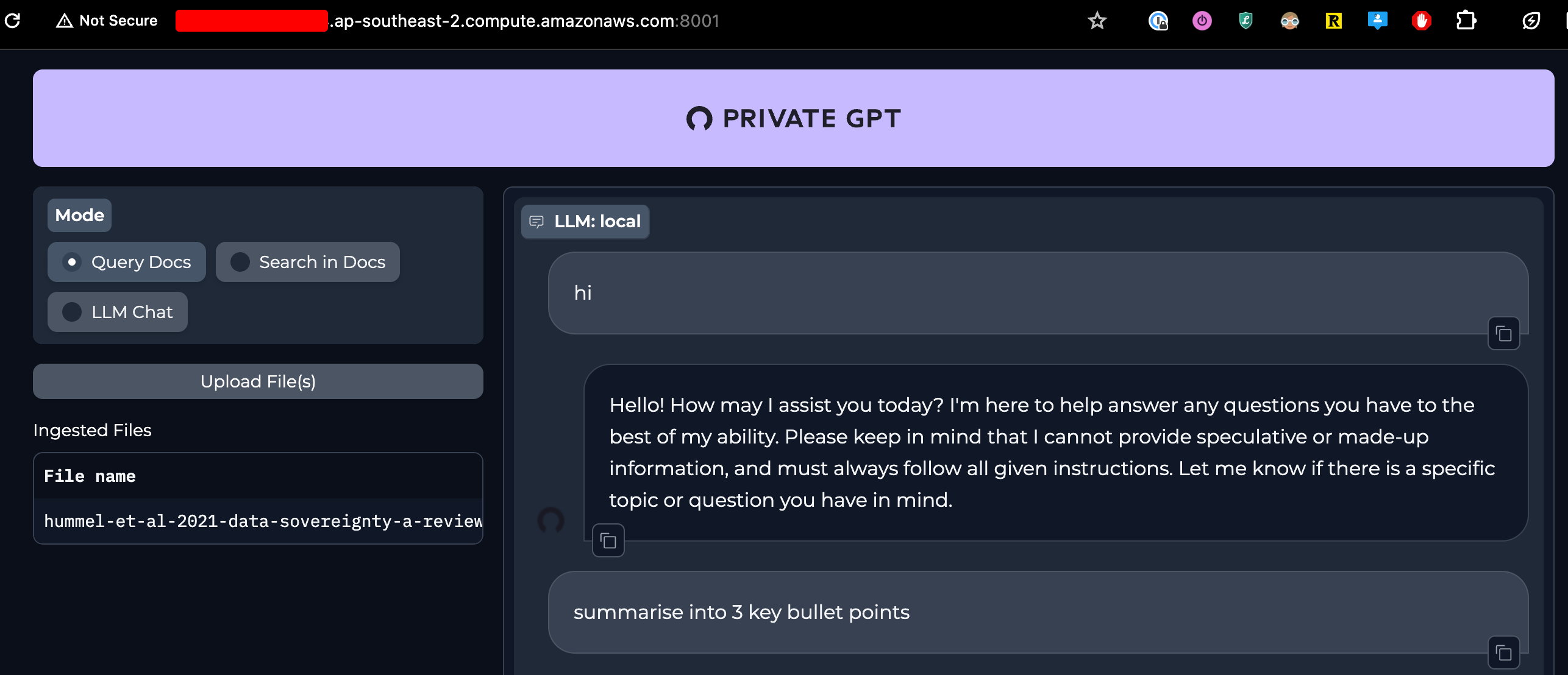
I setup PrivateGPT in previous post locally on Proxmox. Now setting it up on Cloud/AWS to access more compute power.
Requirements
- PrivateGPT: https://github.com/imartinez/privateGPT.git
- Installation Docs: https://docs.privategpt.dev/installation
- Poetry: https://python-poetry.org/docs/#installation
Amazon Web Services (AWS)
I use my own AWS account to launch the EC2 instance where I will install PrivateGPT.
Instance Type
I am using a g4dn.4xlarge EC2 instance.
| Instance Type | vCPUs | Architecture | Memory (GiB) | Instance Storage (GB) | Storage type | Network Bandwidth (Gbps) | On-Demand Price/hr* |
|---|---|---|---|---|---|---|---|
g4dn.4xlarge | 16 | x86_64 | 64 | 225 | SSD | Up to 25Gigabit | 1.566 USD per Hour |
- AMI ID= ami-04f5097681773b989
- Ubuntu Server 22.04 LTS (HVM), SSD Volume Type.
- Description= "Canonical, Ubuntu, 22.04 LTS, amd64 jammy image build on 2023-12-07"
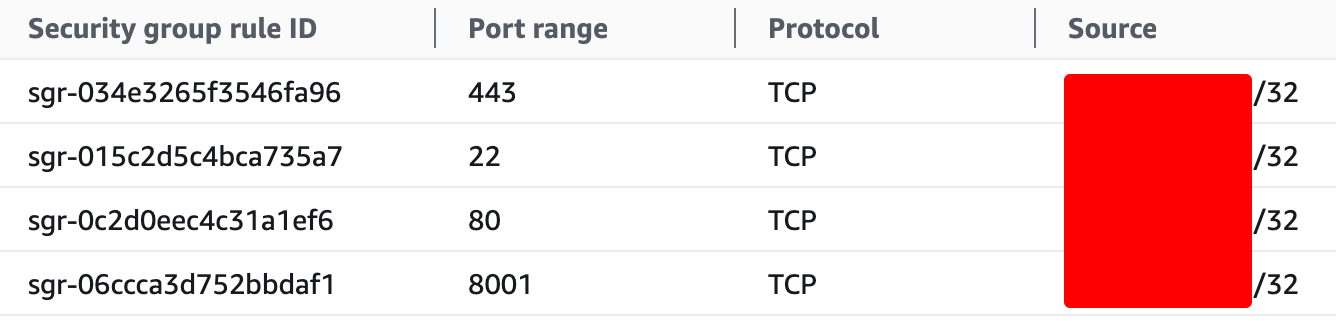
Security Groups
The bare minimum security to set on here is to lock down the following ports to just my IP address on the inbound security group rules.
Ports: 22, 80, 443, 8001 (privateGPT)
Installation
Launch EC2 instance via AWS console, use SSH Keypair to SSH from local terminal to EC2 instance.
Then go ahead with the following commands:
pyenv
Clone PrivateGPT repo:
git clone https://github.com/imartinez/privateGPT
cd privateGPT
Install pyenv, and environment setup:
# install script pyenv
curl https://pyenv.run | bash
# add to ~/.bashrc
# Pyenv
export PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
# reload shell
source ~/.bashrc
# then add this line, and reload shell again
eval "$(pyenv virtualenv-init -)"
Install build dependencies
sudo apt-get update
sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \
libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \
xz-utils tk-dev libffi-dev liblzma-dev git
Install python 3.11 in our pyenv
AWS: when using the Ubuntu Server Pro, 22.04 LTS, amd64 jammy image build on 2023-12-07 ami-0ac438f9a63fdd525 OS, I had a lot of issues with the pyenv install 3.11 command.
Solution: go with the Ubuntu, 22.04 LTS, amd64 jammy image build on 2023-12-07 ami-04f5097681773b989 Free tier AMI.
ubuntu@ip-xxx-xxx-xxx-xxx:~/privateGPT$ pyenv install 3.11
Downloading Python-3.11.7.tar.xz...
-> https://www.python.org/ftp/python/3.11.7/Python-3.11.7.tar.xz
Installing Python-3.11.7...
Installed Python-3.11.7 to /home/ubuntu/.pyenv/versions/3.11.7
Now pyenv local 3.11 to set local version.
Poetry
curl -sSL https://install.python-poetry.org | python3 -
# add to ~/.bashrc
export PATH="/home/ubuntu/.local/bin:$PATH"
test poetry poetry --version
install UI: poetry install --with ui
ubuntu@ip-xxx-xxx-xxx-xxx:~/privateGPT$ poetry install --with ui
Creating virtualenv private-gpt-Wtvj2B-w-py3.11 in /home/ubuntu/.cache/pypoetry/virtualenvs
Installing dependencies from lock file
Package operations: 168 installs, 0 updates, 0 removals
• Installing frozenlist (1.4.1)
• Installing idna (3.6)
• Installing multidict (6.0.4)
• Installing aiosignal (1.3.1)
• Installing attrs (23.1.0)
• Installing certifi (2023.11.17)
• Installing charset-normalizer (3.3.2)
• Installing nvidia-nvjitlink-cu12 (12.3.101)
• Installing six (1.16.0)
• Installing urllib3 (1.26.18)
• Installing wrapt (1.16.0)
• Installing yarl (1.9.4)
• Installing aiohttp (3.9.1): Pending...
• Installing deprecated (1.2.14)
• Installing dill (0.3.7)
• Installing filelock (3.13.1)
• Installing fsspec (2023.12.2)
• Installing aiohttp (3.9.1): Downloading... 0%
• Installing deprecated (1.2.14)
• Installing dill (0.3.7)
• Installing filelock (3.13.1)
• Installing aiohttp (3.9.1)
• Installing deprecated (1.2.14)
• Installing dill (0.3.7)
• Installing filelock (3.13.1)
• Installing fsspec (2023.12.2)
• Installing markupsafe (2.1.3)
• Installing mpmath (1.3.0)
• Installing numpy (1.26.0)
• Installing nvidia-cublas-cu12 (12.1.3.1): Downloading... 40%
• Installing nvidia-cublas-cu12 (12.1.3.1): Installing...
• Installing nvidia-cublas-cu12 (12.1.3.1)
• Installing nvidia-cusparse-cu12 (12.1.0.106)
• Installing packaging (23.2)
• Installing python-dateutil (2.8.2)
• Installing pytz (2023.3.post1)
• Installing pyyaml (6.0.1)
• Installing requests (2.31.0)
• Installing rpds-py (0.14.1)
• Installing tqdm (4.66.1)
• Installing typing-extensions (4.9.0)
• Installing tzdata (2023.3)
• Installing h11 (0.14.0)
• Installing huggingface-hub (0.19.4)
• Installing humanfriendly (10.0)
• Installing jinja2 (3.1.2)
• Installing mdurl (0.1.2)
• Installing multiprocess (0.70.15)
• Installing networkx (3.2.1)
• Installing nvidia-cuda-cupti-cu12 (12.1.105): Downloading... 70%
• Installing nvidia-cuda-nvrtc-cu12 (12.1.105): Downloading... 40%
• Installing nvidia-cuda-runtime-cu12 (12.1.105): Pending...
• Installing nvidia-cuda-cupti-cu12 (12.1.105): Downloading... 80%
• Installing nvidia-cuda-nvrtc-cu12 (12.1.105): Downloading... 40%
• Installing nvidia-cuda-runtime-cu12 (12.1.105): Downloading... 0%
• Installing nvidia-cudnn-cu12 (8.9.2.26): Downloading... 1%
• Installing nvidia-cufft-cu12 (11.0.2.54): Downloading... 0%
• Installing nvidia-curand-cu12 (10.3.2.106): Pending...
• Installing nvidia-cusolver-cu12 (11.4.5.107): Pending...
• Installing nvidia-nccl-cu12 (2.18.1): Pending...
• Installing nvidia-cuda-cupti-cu12 (12.1.105): Installing...
• Installing nvidia-cuda-nvrtc-cu12 (12.1.105): Downloading... 60%
• Installing nvidia-cuda-cupti-cu12 (12.1.105)
• Installing nvidia-cuda-nvrtc-cu12 (12.1.105): Installing...
• Installing nvidia-cuda-nvrtc-cu12 (12.1.105)
• Installing nvidia-cuda-runtime-cu12 (12.1.105)
• Installing nvidia-cudnn-cu12 (8.9.2.26): Downloading... 11%
• Installing nvidia-cudnn-cu12 (8.9.2.26): Downloading... 22%
• Installing nvidia-cufft-cu12 (11.0.2.54): Installing...
• Installing nvidia-cudnn-cu12 (8.9.2.26): Downloading... 39%
• Installing nvidia-cudnn-cu12 (8.9.2.26): Installing...
• Installing nvidia-cudnn-cu12 (8.9.2.26)
• Installing nvidia-cufft-cu12 (11.0.2.54)
• Installing nvidia-curand-cu12 (10.3.2.106)
• Installing nvidia-cusolver-cu12 (11.4.5.107)
• Installing nvidia-nccl-cu12 (2.18.1)
• Installing nvidia-nvtx-cu12 (12.1.105)
• Installing pandas (2.1.4)
• Installing protobuf (4.25.1)
• Installing pyarrow (14.0.1)
• Installing referencing (0.32.0)
• Installing sniffio (1.3.0)
• Installing sympy (1.12)
• Installing triton (2.1.0)
• Installing xxhash (3.4.1)
• Installing annotated-types (0.6.0)
• Installing anyio (3.7.1)
• Installing coloredlogs (15.0.1)
• Installing datasets (2.14.4)
• Installing flatbuffers (23.5.26)
• Installing hpack (4.0.0)
• Installing httpcore (1.0.2)
• Installing hyperframe (6.0.1)
• Installing jmespath (1.0.1)
• Installing jsonschema-specifications (2023.11.2)
• Installing markdown-it-py (3.0.0): Pending...
• Installing mypy-extensions (1.0.0): Pending...
• Installing markdown-it-py (3.0.0): Installing...
• Installing mypy-extensions (1.0.0)
• Installing markdown-it-py (3.0.0)
• Installing mypy-extensions (1.0.0)
• Installing psutil (5.9.6)
• Installing pydantic-core (2.14.5)
• Installing pygments (2.17.2): Installing...
• Installing regex (2023.10.3): Pending...
• Installing responses (0.18.0): Pending...
• Installing safetensors (0.4.1): Pending...
• Installing sentencepiece (0.1.99): Pending...
• Installing pygments (2.17.2)
• Installing regex (2023.10.3)
• Installing responses (0.18.0)
• Installing safetensors (0.4.1)
• Installing sentencepiece (0.1.99)
• Installing tokenizers (0.15.0)
• Installing torch (2.1.2)
• Installing accelerate (0.25.0)
• Installing botocore (1.34.2): Downloading... 90%
• Installing click (8.1.7)
• Installing colorama (0.4.6)
• Installing contourpy (1.2.0)
• Installing botocore (1.34.2): Downloading... 100%
• Installing click (8.1.7)
• Installing colorama (0.4.6)
• Installing botocore (1.34.2): Installing...
• Installing botocore (1.34.2)
• Installing click (8.1.7)
• Installing colorama (0.4.6)
• Installing contourpy (1.2.0)
• Installing cycler (0.12.1)
• Installing distlib (0.3.8)
• Installing distro (1.8.0)
• Installing dnspython (2.4.2)
• Installing evaluate (0.4.1)
• Installing fonttools (4.46.0)
• Installing greenlet (3.0.2)
• Installing grpcio (1.60.0)
• Installing h2 (4.1.0)
• Installing httptools (0.6.1)
• Installing httpx (0.25.2)
• Installing iniconfig (2.0.0)
• Installing joblib (1.3.2)
• Installing jsonschema (4.20.0)
• Installing kiwisolver (1.4.5)
• Installing marshmallow (3.20.1)
• Installing onnx (1.15.0)
• Installing onnxruntime (1.16.3)
• Installing pillow (10.1.0)
• Installing platformdirs (4.1.0)
• Installing pluggy (1.3.0)
• Installing pydantic (2.5.2)
• Installing pyparsing (3.1.1)
• Installing python-dotenv (1.0.0)
• Installing rich (13.7.0)
• Installing shellingham (1.5.4)
• Installing soupsieve (2.5)
• Installing starlette (0.27.0)
• Installing toolz (0.12.0)
• Installing transformers (4.36.1)
• Installing typing-inspect (0.9.0)
• Installing uvloop (0.19.0)
• Installing watchfiles (0.21.0)
• Installing websockets (11.0.3)
• Installing aiofiles (23.2.1)
• Installing aiostream (0.5.2)
• Installing altair (5.2.0)
• Installing beautifulsoup4 (4.12.2)
• Installing cfgv (3.4.0)
• Installing coverage (7.3.3)
• Installing dataclasses-json (0.5.14)
• Installing email-validator (2.1.0.post1)
• Installing fastapi (0.103.2)
• Installing ffmpy (0.3.1): Pending...
• Installing gradio-client (0.7.3)
• Installing grpcio-tools (1.60.0): Pending...
• Installing identify (2.5.33): Pending...
• Installing importlib-resources (6.1.1): Pending...
• Installing itsdangerous (2.1.2): Pending...
• Installing importlib-resources (6.1.1)
• Installing itsdangerous (2.1.2)
• Installing ffmpy (0.3.1): Downloading... 0%
• Installing gradio-client (0.7.3)
• Installing ffmpy (0.3.1)
• Installing gradio-client (0.7.3)
• Installing grpcio-tools (1.60.0)
• Installing identify (2.5.33)
• Installing importlib-resources (6.1.1)
• Installing itsdangerous (2.1.2)
• Installing matplotlib (3.8.2)
• Installing nest-asyncio (1.5.8)
• Installing nltk (3.8.1)
• Installing nodeenv (1.8.0)
• Installing openai (1.5.0)
• Installing optimum (1.16.1)
• Installing orjson (3.9.10)
• Installing pathspec (0.12.1)
• Installing portalocker (2.8.2)
• Installing pydantic-extra-types (2.2.0)
• Installing pydantic-settings (2.1.0)
• Installing pydub (0.25.1)
• Installing pytest (7.4.3)
• Installing python-multipart (0.0.6)
• Installing s3transfer (0.9.0)
• Installing semantic-version (2.10.0)
• Installing sqlalchemy (2.0.23)
• Installing tenacity (8.2.3)
• Installing tiktoken (0.5.2)
• Installing tomlkit (0.12.0)
• Installing typer (0.9.0)
• Installing ujson (5.9.0)
• Installing uvicorn (0.24.0.post1)
• Installing virtualenv (20.25.0)
• Installing black (22.12.0): Installing...
• Installing black (22.12.0)
• Installing boto3 (1.34.2)
• Installing gradio (4.10.0): Downloading... 50%
• Installing injector (0.21.0)
• Installing llama-index (0.9.3)
• Installing gradio (4.10.0)
• Installing injector (0.21.0)
• Installing llama-index (0.9.3)
• Installing mypy (1.7.1)
• Installing pre-commit (2.21.0)
• Installing pypdf (3.17.2)
• Installing pytest-asyncio (0.21.1)
• Installing pytest-cov (3.0.0)
• Installing qdrant-client (1.7.0)
• Installing ruff (0.1.8)
• Installing types-pyyaml (6.0.12.12)
• Installing watchdog (3.0.0)
Installing the current project: private-gpt (0.2.0)
ubuntu@ip-xxx-xxx-xxx-xxx:~/privateGPT$
install poetry with local: poetry install --with local
ubuntu@ip-xxx-xxx-xxx-xxx:~/privateGPT$ poetry install --with local
Installing dependencies from lock file
Package operations: 7 installs, 0 updates, 0 removals
• Installing scipy (1.11.4)
• Installing threadpoolctl (3.2.0)
• Installing diskcache (5.6.3)
• Installing scikit-learn (1.3.2)
• Installing torchvision (0.16.2)
• Installing llama-cpp-python (0.2.23)
• Installing sentence-transformers (2.2.2)
Installing the current project: private-gpt (0.2.0)
Runtime
Run setup: poetry run python scripts/setup
ubuntu@ip-xxx-xxx-xxx-xxx:~/privateGPT$ poetry run python scripts/setup
00:16:27.904 [INFO ] private_gpt.settings.settings_loader - Starting application with profiles=['default']
Downloading embedding BAAI/bge-small-en-v1.5
config_sentence_transformers.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████��██████████████████| 124/124 [00:00<00:00, 1.03MB/s]
modules.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 349/349 [00:00<00:00, 3.44MB/s]
.gitattributes: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.52k/1.52k [00:00<00:00, 14.5MB/s]
README.md: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 90.3k/90.3k [00:00<00:00, 453kB/s]
config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 743/743 [00:00<00:00, 6.94MB/s]
1_Pooling/config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 190/190 [00:00<00:00, 2.03MB/s]
sentence_bert_config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 52.0/52.0 [00:00<00:00, 601kB/s]
tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 366/366 [00:00<00:00, 3.47MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████████████████████████████████�█████████████████████████████████████████████████████| 125/125 [00:00<00:00, 1.22MB/s]
vocab.txt: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 232k/232k [00:00<00:00, 592kB/s]
tokenizer.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 711k/711k [00:00<00:00, 912kB/s]
model.safetensors: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 133M/133M [00:09<00:00, 14.4MB/s]
pytorch_model.bin: 100%|███████████████████████████████████████████████�████████████████████████████████████████████████████████████████████████████| 134M/134M [00:10<00:00, 13.2MB/s]
Fetching 13 files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:12<00:00, 1.02it/s]
Embedding model downloaded!█████████████████████████████████████████████████████████████████████████████████████████████▌ | 105M/134M [00:08<00:01, 15.9MB/s]
Downloading LLM mistral-7b-instruct-v0.2.Q4_K_M.gguf███████████████████████████████████████████████████████████████████████████████████████████████| 134M/134M [00:10<00:00, 15.7MB/s]
mistral-7b-instruct-v0.2.Q4_K_M.gguf: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 4.37G/4.37G [00:09<00:00, 451MB/s]
LLM model downloaded!
Downloading tokenizer mistralai/Mistral-7B-Instruct-v0.2
tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.46k/1.46k [00:00<00:00, 12.1MB/s]
tokenizer.model: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 493k/493k [00:00<00:00, 369MB/s]
tokenizer.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.80M/1.80M [00:00<00:00, 3.04MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 72.0/72.0 [00:00<00:00, 770kB/s]
Tokenizer downloaded!
Setup done
ubuntu@ip-xxx-xxx-xxx-xxx:~/privateGPT$
Launch PrivateGPT API and start the UI.
Because we've gone with poetry for dependencies, we launch PrivateGPT with poetry
poetry run python -m private_gpt
ubuntu@ip-172-31-3-217:~/privateGPT$ poetry run python -m private_gpt
00:55:51.178 [INFO ] private_gpt.settings.settings_loader - Starting application with profiles=['default']
00:55:56.198 [INFO ] private_gpt.components.llm.llm_component - Initializing the LLM in mode=local
llama_model_loader: loaded meta data with 24 key-value pairs and 291 tensors from /home/ubuntu/privateGPT/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf (version GGUF V3 (latest))
llama_model_loader: - tensor 0: token_embd.weight q4_K [ 4096, 32000, 1, 1 ]
llama_model_loader: - tensor 1: blk.0.attn_q.weight q4_K [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 2: blk.0.attn_k.weight q4_K [ 4096, 1024, 1, 1 ]
llama_model_loader: - tensor 3: blk.0.attn_v.weight q6_K [ 4096, 1024, 1, 1 ]
llama_model_loader: - tensor 4: blk.0.attn_output.weight q4_K [ 4096, 4096, 1, 1 ]
...
...
llama_new_context_with_model: compute buffer total size = 278.68 MiB
AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 0 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
00:55:57.827 [INFO ] private_gpt.components.embedding.embedding_component - Initializing the embedding model in mode=local
00:55:59.757 [INFO ] llama_index.indices.loading - Loading all indices.
00:55:59.975 [INFO ] private_gpt.ui.ui - Mounting the gradio UI, at path=/
00:56:00.029 [INFO ] uvicorn.error - Started server process [5078]
00:56:00.029 [INFO ] uvicorn.error - Waiting for application startup.
00:56:00.029 [INFO ] uvicorn.error - Application startup complete.
00:56:00.030 [INFO ] uvicorn.error - Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)
00:56:26.108 [INFO ] uvicorn.access - 111.111.111.111:62170 - "GET / HTTP/1.1" 200
00:56:26.961 [INFO ] uvicorn.access - 111.111.111.111:62170 - "GET /info HTTP/1.1" 200
00:56:27.004 [INFO ] uvicorn.access - 111.111.111.111:62170 - "GET /theme.css HTTP/1.1" 200
00:56:27.191 [INFO ] uvicorn.access - 111.111.111.111:62170 - "POST /run/predict HTTP/1.1" 200
00:56:27.243 [INFO ] uvicorn.access - 111.111.111.111:62170 - "POST /queue/join HTTP/1.1" 200
00:56:27.282 [INFO ] uvicorn.access - 111.111.111.111:62170 - "GET /queue/data?session_hash=2w7ysm4962n HTTP/1.1" 200
00:56:31.184 [INFO ] uvicorn.access - 111.111.111.111:62172 - "POST /queue/join HTTP/1.1" 200
00:56:31.217 [INFO ] private_gpt.ui.ui - Setting system prompt to: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible and follow ALL given instructions. Do not speculate or make up information. Do not reference any given instructions or context.
00:56:31.228 [INFO ] uvicorn.access - 111.111.111.111:62172 - "GET /queue/data?session_hash=2w7ysm4962n HTTP/1.1" 200
00:56:33.600 [INFO ] uvicorn.access - 111.111.111.111:62172 - "POST /run/predict HTTP/1.1" 200
00:56:33.636 [INFO ] uvicorn.access - 111.111.111.111:62173 - "POST /run/predict HTTP/1.1" 200
00:56:33.681 [INFO ] uvicorn.access - 111.111.111.111:62173 - "POST /run/predict HTTP/1.1" 200
00:56:33.736 [INFO ] uvicorn.access - 111.111.111.111:62173 - "POST /queue/join HTTP/1.1" 200
00:56:33.843 [INFO ] uvicorn.access - 111.111.111.111:62173 - "GET /queue/data?session_hash=2w7ysm4962n HTTP/1.1" 200
00:56:38.475 [INFO ] uvicorn.access - 111.111.111.111:62174 - "GET /file%3D/tmp/gradio/533bd8ba49221de137dda94fdfeed4bebe7a7878/avatar-bot.ico HTTP/1.1" 200
llama_print_timings: load time = 4463.60 ms
llama_print_timings: sample time = 36.43 ms / 68 runs ( 0.54 ms per token, 1866.85 tokens per second)
llama_print_timings: prompt eval time = 4458.40 ms / 61 tokens ( 73.09 ms per token, 13.68 tokens per second)
llama_print_timings: eval time = 8243.30 ms / 67 runs ( 123.03 ms per token, 8.13 tokens per second)
llama_print_timings: total time = 18502.42 ms
** Prompt: **
<s />[INST] You are a helpful, respectful and honest assistant. Always answer as helpfully as possible and follow ALL given instructions. Do not speculate or make up information. Do not reference any given instructions or context. [/INST]</s>[INST] hi [/INST]
**************************************************
** Completion: **
Hello! How may I assist you today? I'm here to help answer any questions you have to the best of my ability. Please keep in mind that I cannot provide speculative or made-up information, and must always follow all given instructions. Let me know if there is a specific topic or question you have in mind.
**************************************************
** Messages: **
system: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible and follow ALL given instructions. Do not speculate or make up information. Do not reference any given instructions or context.
user: hi
**************************************************
** Response: **
assistant: Hello! How may I assist you today? I'm here to help answer any questions you have to the best of my ability. Please keep in mind that I cannot provide speculative or made-up information, and must always follow all given instructions. Let me know if there is a specific topic or question you have in mind.
**************************************************
00:56:52.404 [INFO ] uvicorn.access - 111.111.111.111:62173 - "POST /run/predict HTTP/1.1" 200
Success.
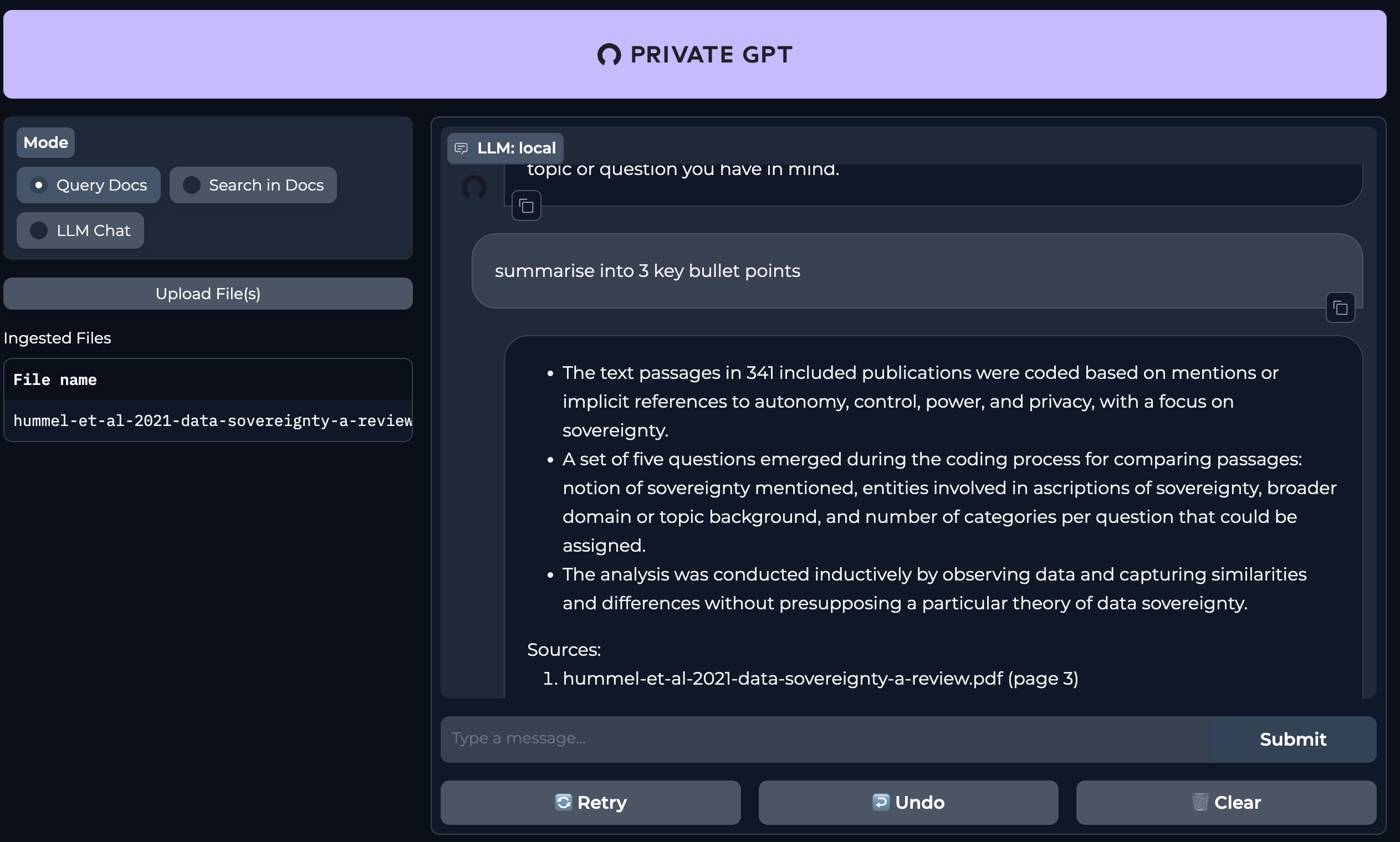
Chat Function:
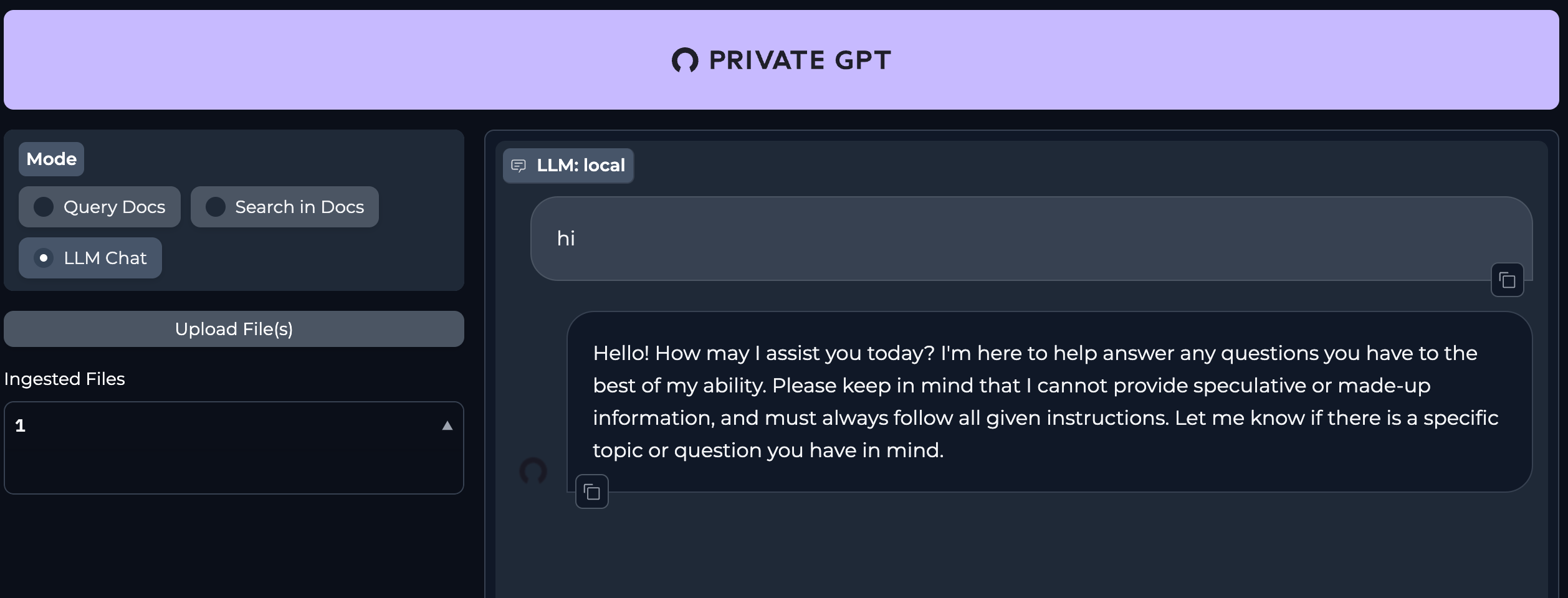
Query Document that has been uploaded:
- ingestion process i.e. chunking and embedding the doc was noticable faster here than in my local privateGPT setup in previous post.
- the summary given here, imo, was not great (using Mistral7B model).
Troubleshooting
Errors: "Collection make_this_parameterizable_per_api_call not found" on the UI.
# from stdout
...
File "/home/ubuntu/.cache/pypoetry/virtualenvs/private-gpt-Wtvj2B-w-py3.11/lib/python3.11/site-packages/qdrant_client/local/qdrant_local.py", line 121, in _get_collection
raise ValueError(f"Collection {collection_name} not found")
ValueError: Collection make_this_parameterizable_per_api_call not found
...
related and further down the stdout output:
...
AttributeError: 'NoneType' object has no attribute 'split'
...
I'm assuming the split is happening on a None cos the collection can't be found further up.
Solution
I restarted the process a few times trying to figure out what the problem was, gave same error couple of times, then magically after another restart it all started working again. smh.
Appendix
Notes from looking at different components.
From ChatGPT:
For running Mistral 7xb, I would suggest starting with a p4d.24xlarge instance due to its superior computational capabilities and memory. However, if budget constraints are a concern, a g4dn.12xlarge instance can be a viable alternative. Always monitor the performance and adjust the specifications as needed.
p4d.24xlarge specs =
g4dn.12xlarge specs =
region = ap-southeast-2
g5.12xlarge
GPU or no GPU?
It's the "inference" part of the LLM architecture that needs GPU for generation, but a high-powered CPU could be enough if your app is just processing requests out to the user.
ChatGPT had some interesting points to note:
Model Size: Larger models with more parameters (like GPT-3's 175 billion parameters) require more computational power for inference. Smaller models might be efficiently run on CPUs or less powerful GPUs.
Inference Load: The number of queries your application processes simultaneously affects GPU requirements. High query volumes or the need for rapid responses can necessitate more powerful GPUs.
Complexity of Tasks: More complex queries, such as those requiring understanding of longer contexts or generating lengthy responses, can increase computational demands.
Optimization and Quantization: Models optimized for inference, potentially using techniques like quantization (reducing the precision of the model's parameters), can reduce GPU requirements.
GPU vs CPU Inference: While GPUs are generally faster for model inference due to their parallel processing capabilities, some applications might run satisfactorily on modern CPUs, especially if inference demands are low.
I had to request an increase in vCPU of G* EC2 instances for Region us-east-1, quota was zero, requested 48 vCPU
Created an EC2 Instance on AWS Cloud, running:
| Instance Size | GPU | vCPUs | Memory (GiB) | Instance Storage (GB) | Network Bandwidth (Gbps) | EBS Bandwidth (Gbps) | On-Demand Price/hr* |
|---|---|---|---|---|---|---|---|
| g4dn.12xlarge | 4 | 48 | 192 | 1 x 900 NVMe SSD | 50 | 9.5 | $3.192 |