Retrieval Augmented Generation (RAG) - Production-Ready AI Applications Guide
I'm watching "Building Production-Ready RAG Applications: Jerry Liu" video.
Two Paradigms:
- Fixed Model + Retrieval Augmentation
- Fine-tuning
That "chat with docs" archticture ("RAG stack"), is mainly the following pattern:
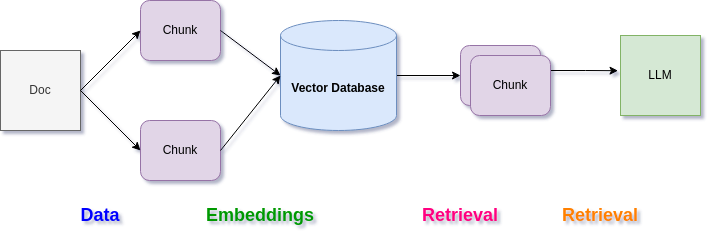
- Data
- Embeddings
- Retrieval
- Synthesis
Challenges
"Naive" RAG:
- Retrieval process has issues e.g. log precision ("lost in the middle"), low recall (needs enough context)
- Model itself has issues e.g. hallucinations, relevance, toxicity
How do we improve?
Looking at each step of the process - data, embeddings, retrieval and synthesis - and seeing if we can improve the component parts.
Can you optimize... the data used? The way its embeddings are generated? The retrieval algorithm, can it be improved? Sythesis - can it be used to "reason over the data" and not just "generate and serve" the answer?
in order to improve anything you need to be task specific in what you're going to measure and why.
Evaluate a RAG system
two ways to evaluate i.e. benchmark: components, and fully e2e.
by component: e.g. retrieval, create a dataset synthetically if you don't have one, run retriever over dataset, measure ranking metrics.
fully end-to-end(e2e): e.g. synthesis, create dataset, run through RAG, collect metrics (no labels, labels).
Optimise RAG system
Things to work on from simplest/cheapest, to most advanced/expensive:
- Table stakes: better parsers, chunk sizes, hybrid search, metadata filters
- Advanced Retrieval: reranking, recursive retrieval, embedded tables, small-to-big rets.
- Fine-tuning: embedded fine-tuning, LLM fine-tuning
- Agentic Behaviour: Routing, Query Planning, Multi-doc Agents
Reference
Talk was from a LlamaIndex engineer