Claude 3 Opus Financial Advisor - AI-Powered Personal Finance Assistant
This project is my notes and code for a Financial Advisor that I'm designing and building using Claude 3 Opus.
I'm scratching a couple of itches with this project
- Learn how to build AI applications.
- Using an LLM to learn and build an entire project.
I will link the initial design doc here
Project Folder Structure
can you please give me the best practice python application folder structure for this
financial_analyzer/
├── app/
│ ├── __init__.py
│ ├── data/
│ │ ├── __init__.py
│ │ ├── data_ingestion.py
│ │ └── preprocessing.py
│ ├── models/
│ │ ├── __init__.py
│ │ └── claude_api.py
│ ├── analysis/
│ │ ├── __init__.py
│ │ ├── insights.py
│ │ └── metrics.py
│ ├── visualization/
│ │ ├── __init__.py
│ │ ├── charts.py
│ │ └── report.py
│ └── utils/
│ ├── __init__.py
│ └── helpers.py
├── tests/
│ ├── __init__.py
│ ├── test_data_ingestion.py
│ ├── test_preprocessing.py
│ ├── test_claude_api.py
│ ├── test_insights.py
│ ├── test_metrics.py
│ ├── test_charts.py
│ └── test_report.py
├── data/
│ ├── raw/
│ └── processed/
├── docs/
│ ├── README.md
│ └── api_docs.md
├── notebooks/
│ └── exploratory_analysis.ipynb
├── reports/
│ └── generated_reports/
├── config/
│ └── config.py
├── requirements.txt
├── setup.py
└── main.py
Explain Folder Structure
-
app/: Contains the main application code.data/: Handles data ingestion and preprocessing.data_ingestion.py: Code for reading CSV and PDF files.preprocessing.py: Code for data cleaning, categorization, and preprocessing.
models/: Handles interaction with the Claude 3 Opus API.claude_api.py: Code for generating embeddings and retrieving transactions using the Claude 3 Opus API.
analysis/: Handles data analysis and insights generation.insights.py: Code for generating insights and summaries using the Claude 3 Opus API.metrics.py: Code for calculating key metrics.
visualization/: Handles data visualization and report generation.charts.py: Code for creating visualizations using Matplotlib or other libraries.report.py: Code for generating PDF reports using ReportLab or other libraries.
utils/: Contains utility functions and helper modules.helpers.py: Code for common utility functions used across the application.
-
tests/: Contains unit tests for different modules of the application. -
data/: Stores the raw and processed data files.raw/: Contains the raw input data files (CSV or PDF).processed/: Contains the preprocessed data files.
-
docs/: Contains documentation files.README.md: Provides an overview and instructions for the project.api_docs.md: Contains documentation for the Claude 3 Opus API usage.
-
notebooks/: Contains Jupyter notebooks for exploratory analysis and experimentation. -
reports/: Stores the generated PDF reports.generated_reports/: Contains the generated PDF reports.
-
config/: Contains configuration files.config.py: Stores configuration variables and settings for the application.
-
requirements.txt: Lists the project dependencies and their versions. -
setup.py: Contains setup configuration for the project. -
main.py: The entry point of the application.
This folder structure organizes the codebase into logical modules and separates concerns. It promotes code reusability, maintainability, and ease of testing. You can adjust the structure based on your specific requirements and preferences.
Remember to keep sensitive information, such as API keys, in a separate configuration file or environment variables, and avoid committing them to version control.
Setup Script
See "project setup script" in the Appendix below.
Paste this script into finad.sh, then chmod +x ./finad.sh then ./finad.sh.
You'll get:
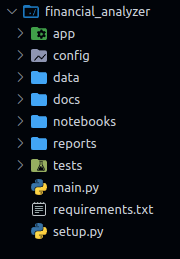
Let's start coding.
Code
Step 1: Set up the project and install dependencies
-
Set up and activate a virtual environment.
python3 -m venv .env
~/Repositories/financial_analyzer ❯ source .env/bin/activate at 17:39:23
~/Repositories/financial_analyzer ❯ .env at 17:39:45 -
Install the necessary libraries:
# add to requirements.txt
pandas
numpy
matplotlib
reportlab
anthropic
# install
pip install -r requirements.txt
Step 2: Data Ingestion and Preprocessing
-
In the file
app/data/data_ingestion.pyand add the following code:import pandas as pd
def read_csv(file_path):
df = pd.read_csv(file_path)
return df
def read_pdf(file_path):
# Implement code to read and parse PDF files
pass -
Open
app/data/preprocessing.pyfile and add the following code:def preprocess_data(df):
# Perform data cleaning, categorization, and preprocessing tasks
# Example:
df['Date'] = pd.to_datetime(df['Date'])
df['Amount'] = df['Amount'].astype(float)
return df
Step 3: Interaction with Claude 3 Opus API
-
Open the
app/models/claude_api.pyfile and add the following codefrom anthropic import Claude
def generate_embeddings(df, api_key):
claude = Claude(api_key)
# Transform the preprocessed data into a format suitable for Claude 3 Opus
# Generate embeddings for each transaction or category using the Claude 3 Opus API
# Example:
embeddings = []
for _, row in df.iterrows():
prompt = f"Transaction: {row['Description']}\nAmount: {row['Amount']}\nDate: {row['Date']}"
response = claude.generate(prompt)
embeddings.append(response.generations[0].text)
return embeddings
def retrieve_transactions(query, embeddings):
# Implement similarity search or query-based retrieval using the generated embeddings
# Return the relevant transactions based on the query
pass
Appendix
project setup script
#!/bin/bash
# Create the main project directory
mkdir financial_analyzer
cd financial_analyzer
# Create the app directory and its subdirectories
mkdir -p app/{data,models,analysis,visualization,utils}
touch app/{__init__.py,data/{__init__.py,data_ingestion.py,preprocessing.py},models/{__init__.py,claude_api.py},analysis/{__init__.py,insights.py,metrics.py},visualization/{__init__.py,charts.py,report.py},utils/{__init__.py,helpers.py}}
# Create the tests directory and test files
mkdir tests
touch tests/{__init__.py,test_data_ingestion.py,test_preprocessing.py,test_claude_api.py,test_insights.py,test_metrics.py,test_charts.py,test_report.py}
# Create the data directory and its subdirectories
mkdir -p data/{raw,processed}
# Create the docs directory and documentation files
mkdir docs
touch docs/{README.md,api_docs.md}
# Create the notebooks directory and a sample notebook
mkdir notebooks
touch notebooks/exploratory_analysis.ipynb
# Create the reports directory and its subdirectory
mkdir -p reports/generated_reports
# Create the config directory and configuration file
mkdir config
touch config/config.py
# Create other project files
touch {requirements.txt,setup.py,main.py}